Building peer-to-peer networks is hard. Figuring out how to test them can be even harder.
As the launch of the Corea milestone — the biggest Streamr Network upgrade so far — is drawing nearer, I thought it might be good to give an overview of the goals for this release, as well as how we’ve gone about building and testing the new network.
Table of Contents
Design Principles
For the Streamr Network, we’ve always had certain goals in mind. When we started working on Corea in August 2018, we applied this set of goals to help us make the right decisions about what would (and what would not) be included in the milestone.
- Scalability: The Network should scale without limit, meaning that the Network will continue providing good quality of service no matter how many nodes are added to it. Also, the load of the data publisher should stay constant regardless of the number of subscribers.
- Decentralization: The Network should not have hotspots or require central points of failure to operate.
- Low and predictable latency: The event propagation delay should stay low in all situations. Also, the relative path penalty should be small if compared to having direct connections to the publishers.
- Optimisation for small payloads (telemetry, IoT): The network should be optimised for transmitting large numbers of small messages, in contrast to transmitting small numbers of large messages.
- Bandwidth efficiency: The number of unnecessary messages transmitted in the Network should be low. A node should only receive a small number of duplicates of each message.
- Message completeness: A node should receive all the messages of a stream it is subscribed to with a high probability, provide means to detect missed messages, and a mechanism to have them resent.
- Robustness: The Network should be reliable in real-life use. The implementation should be kept simple, and easy to debug.
Diving into existing literature and having these goals in mind quickly led us onto a certain track and certain decisions. For example, we realised the beneficial properties of random-topology networks, and selected that as a starting point for per-stream topologies in the Corea network.
In contrast, in the 2017 white paper, we envisioned the Streamr Network to be more like a “decentralized Kafka”, with a tree-like topology that had a predetermined replication factor and a predetermined number of partitions spanning all streams in the network.
However, the random-topology-per-stream approach provides much better robustness and churn tolerance while providing decent performance and leaving the door open for various dynamic performance optimisations in later milestones. Should the rigid, tree-like topology originally envisioned turn out to be the best one, it should be discovered and converged on dynamically by the Network, not hard-coded in advance.
In addition to the normal data-brokering behaviour in the network nodes, we introduced two other roles into the Network: storage nodes and trackers. Storage nodes are responsible for long-term data archival and subscribe to large subsets of data passing through the Network.
Trackers govern the formation of the topology for a particular stream by “introducing” nodes that are interested in a given stream to each other. The network can have any number of normal nodes, storage nodes, and trackers to avoid single points of failure.
All the planned Streamr Network milestones are intended to be drop-in replacements for the previous generation
Obviously, Corea is not the end of the road. This milestone mostly focuses on implementing the highly distributed message brokering functionality. Most notably, the token economics are not yet included in this milestone, and will only be introduced during the next two milestones: Brubeck and Tatum. Corea also still depends on the centralized backend to serve a registry of stream permissions to nodes and client apps, whereas this information will later be on-chain and thus made available in a decentralized way.
How do you build and test a P2P network?
By late 2018, we had already built a working prototype with one tracker, no storage nodes, and a small number of normal nodes, successfully brokering messages in one stream. That was a great start, but we had some important questions to answer. How would the Network function if there were thousands of nodes? And what if there were millions of streams, or millions of subscribers to them? What if the nodes went down randomly, or the Network links between the nodes broke? What would happen to related stream topologies if a tracker went down? What if the nodes became overwhelmed and couldn’t handle the volume of data?
To answer these questions, much of the work in making Corea production-ready has gone into validation: stress testing, scalability testing, performance testing, and ensuring functional backwards-compatibility with the previous-generation Network, Monk.
By setting up long-running real-world testnets, we were able to uncover problems that build up over time
All the planned Streamr Network milestones are intended to be drop-in replacements for the previous generation — meaning that the Core app, Marketplace, and all other applications using Streamr via the APIs should not need any changes to be compatible with the upgrade, even though, under the hood, the whole of the Network’s architecture is changing.
Emulated Networks
One of the most important tools in testing Corea at scale has been network emulation. Emulation allows us to run a number of nodes on the same physical machine (where the main constraints are the available memory and CPU), with nodes connected over an emulated network instead of a real physical over-the-internet connection. This environment allows us to precisely set bandwidths, latencies, and jitter, as well as introduce malfunctions to the connections.
The CORE network emulator became our tool of choice. It’s open-source and developed by the U.S. Naval Research Laboratory. While it’s not the newest or sexiest software you’ve ever seen, it’s very battle-tested and works on all platforms.
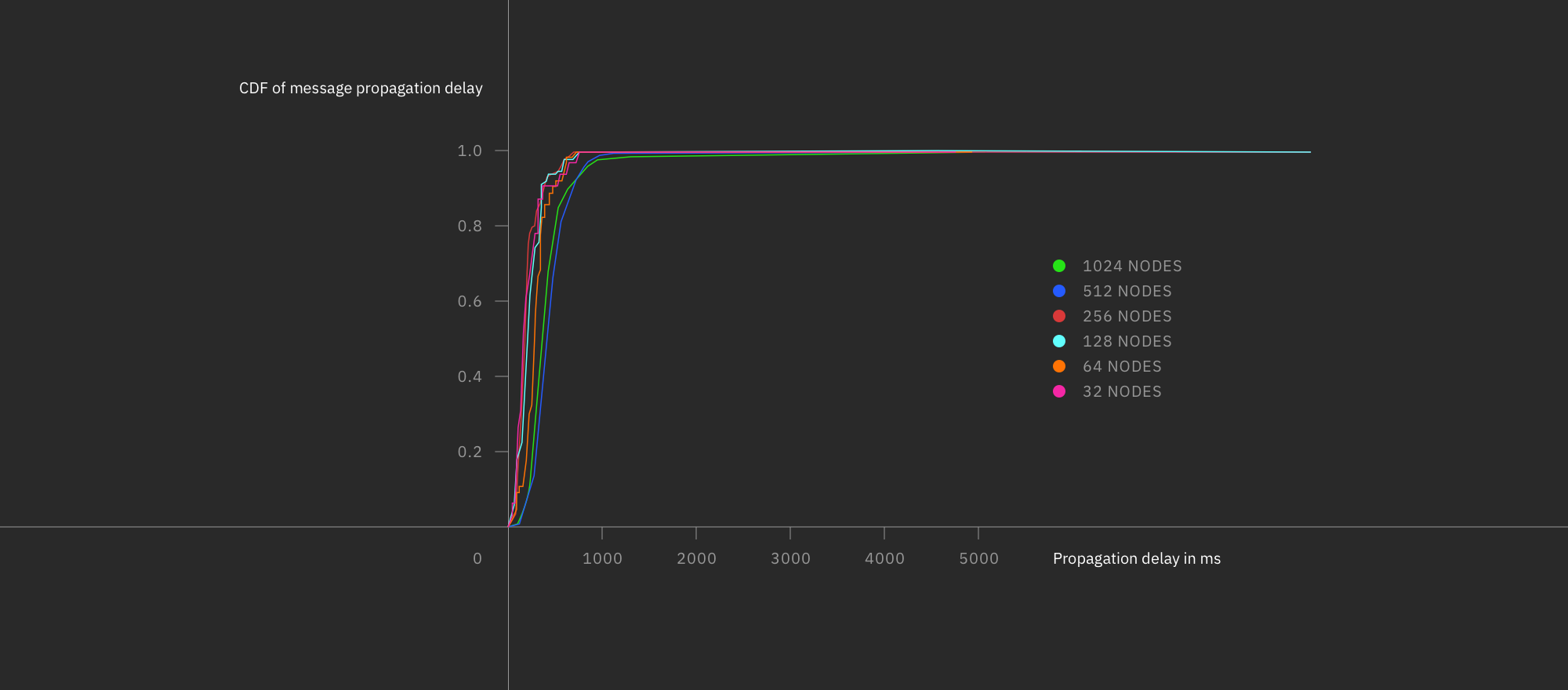
Emulating networks allowed us to measure latencies and duplicate messages in larger-scale networks up to thousands of nodes, and helped validate that the Corea code was behaving correctly; the topologies were stable, data was reaching subscribers, and so on.
However, as emulated networks were spun up, measured, and then terminated, this mode of testing didn’t allow us to see how things behave over longer periods of time. Another form of testing was required to complement the emulated networks.
Real-world Testnets
Firstly, by setting up long-running real-world testnets, we were able to uncover problems that build up over time, such as memory leaks. Secondly, in the emulated setup, some of the CPU cycles go into running the network emulation (as opposed to running the node), so stress testing the nodes and measuring actual CPU usage make sense only in a real environment. And finally, real testnets are subject to the unpredictability of actual internet connections, revealing how the network operates in practice under real-world conditions.
Compared to emulated networks, it’s not that easy to run testnets at scale. Sure, tens or even hundreds of nodes can be started quite easily using cloud services, but scaling to thousands of nodes is starting to hit the limits of what those platforms can do. Beyond a certain scale, this approach also becomes prohibitively expensive.
So, with the above pros and cons in mind, our testnets were focused on validating behaviour over time under real-world conditions. Because the goal of the Corea release is to replace the previous-generation network, Monk, our longest-running experiment is an eight-node testnet to which we replicate all data published to Monk. That’s currently around 6000 messages per second, as you can see in real-time on the Network page. Although this doesn’t fully represent everything that’s happening in the old network (for example, it doesn’t include real-world subscribers such as Core canvases and API users), it still gives us reasonable assurance that everything will work fine once we swap Monk for Corea.
Interestingly, we leveraged the old Network and Streamr Core in measuring the testnets in real-time. The stack is actually quite suitable for this type of use case! Corea nodes were configured to regularly publish metrics to a stream, which we then monitored in real-time using canvases, one of which you can view here.
While Corea seems to be well equipped to handle the current production load, it’s still early days in terms of serious adoption. We need to prepare for several orders of magnitude and more traffic in the future. At the time of writing this, we’re setting up scripts to spin up a globally distributed network with nodes running in all available AWS zones, which we then plan to test under considerable load equivalent to an enterprise-level use case, with hundreds of thousands of devices publishing data onto the network.
White Paper and Next Steps
The network R&D team will be releasing a white paper on Corea later this year, detailing the reasons behind the architectural choices we’ve made and the experiments we’ve run, as well as the results obtained. While the paper might be of some academic interest, the primary purpose of the paper will be to provide in-depth information about the characteristics of the Corea network to serious players such as enterprises, governments, and other large organisations, seeking to utilise the Network at scale.
The next steps in the deployment of Corea are to double-check that all the pieces fit well together, and then finally do the switch from Monk to Corea. If all goes well, Streamr Core, Marketplace, and the API gateways will all point to Corea mainnet just in time for Devcon5. In fact, we’re hosting a P2P (pier-to-pier!) boat party to celebrate the release of Corea.
See you there!
Have questions? Join our community developer forum and ask away!




