Scalability is the superpower of a decentralized peer-to-peer (P2P) network. It can be achieved in its purest form when each participant contributes resources instead of relying on centralized servers or super-nodes.
In traditional Web3 architectures, we often see “full nodes” serving data to many “light nodes,” which starts to resemble a client–server bottleneck — add more clients, and you need more powerful servers. This was the track Streamr was on during the “Brubeck Era” of the project, when the core team ran tracker nodes to coordinate the P2P connections that data streams are transported on within the Streamr Network.
In the “1.0” Milestone, we took a different approach: we dropped the tracker model and instead made every node a full node — even if it’s just a web browser on your laptop. This is the current trackerless network architecture: fully decentralized. The trackers were replaced with an ambitious, multi-layer Distributed Hash Table (DHT) design that allows nodes to orient themselves independently while enabling the network to scale gracefully.
In Part 1 of this blog series, we’ll first unpack this novel three-layer architecture that minimizes heavy lifting for each node while still achieving full decentralization. In Part 2, we’ll share the scalability experiments that prove the new architecture performs at massive scale.
Table of Contents
The three layers of the Streamr Network
Each of the three layers has a distinct role and scope. Together, they replace a tracker-based system with a fully decentralized coordination mechanism. On Streamr, there is no global gossip. In some P2P designs, every message is flooded — or at least announced — to the entire network, which creates noise and slows everything down. Streamr’s multi-layer structure avoids this with its novel three-layer architecture.
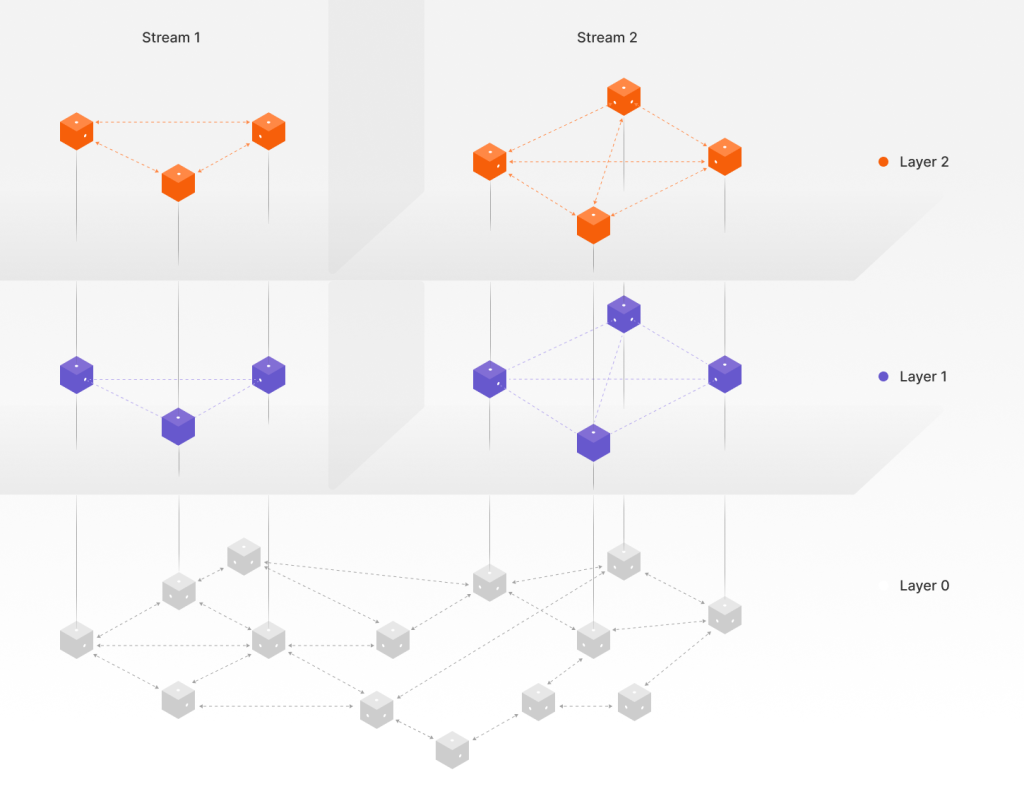
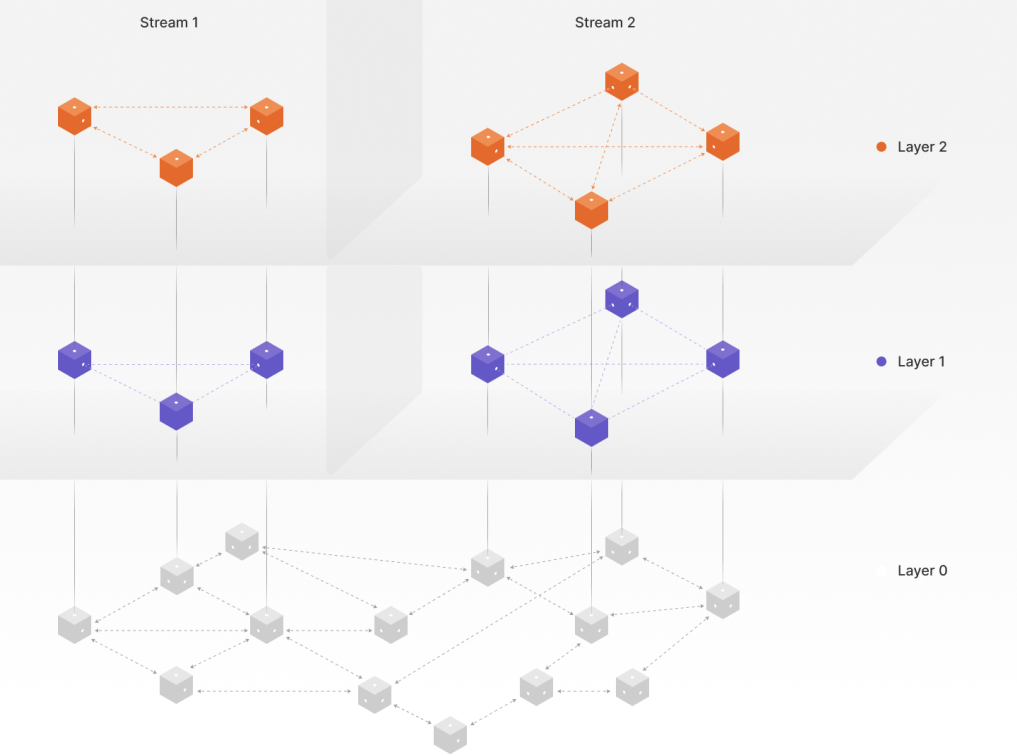
Figure 1: A conceptual diagram of Streamr’s three-layer architecture.
Layer 0: The Global Kademlia DHT
Layer 0 is an r-Kademlia distributed hash table spanning all nodes in the network. Think of it as a worldwide “phone book” or highway system that any node can use to find any other node or resource. This layer’s responsibilities include bootstrapping new nodes (helping them join the network), storing and looking up metadata (like “entry points” for data streams), and routing messages from any node to any other via a series of hops if they aren’t directly connected.
When a new node comes online, it contacts a few known peers and inserts itself into this DHT. From then on, it maintains a small number of ongoing connections (to its DHT neighbors) and can route messages through the network. Layer 0 is essentially the backbone — it ensures every node is reachable in just a few hops.
Layer 1: Hybrid DHT for Stream Coordination
If Layer 0 is the global highway, Layer 1 is the local roads specific to each data stream. Each stream (topic) has its own DHT-based overlay network for peer discovery. Layer 1 is called a hybrid DHT because it blends two schemes: a standard Kademlia DHT (for global robustness) and a locality-aware ring DHT (for geographic closeness). Its job is to discover peers in stream partitions — some nearby for speed, some farther for robustness.
Layer 1 is fully connectionless and uses Layer 0’s routing functionality to pass messages. This reduces the total number of connections in the network.
Layer 2: Mesh Network, for Stream Data Delivery
Finally, Layer 2 is where the actual data — the real-time messages — flows for each stream. It’s a mesh network composed of the nodes subscribed to that stream, typically using direct connections between those nodes. If Layer 1 provides a list of nodes for a stream, your node will establish direct P2P connections with at least four of them.
Layer 2 is location-aware thanks to Layer 1’s input, meaning you’ll likely connect to geographically close nodes, which helps keep latency low. Once the mesh is formed, any data published to the stream is broadcast across it so that all subscribers receive it.
How the layers work together
When a node wants to join a stream, it:
- Uses Layer 0 to find the stream’s entry point in the network.
- Uses Layer 1 to discover peers in that stream.
- Connects on Layer 2 to start receiving data.
Because of this layered approach, nodes don’t need to maintain a large number of direct connections. They reuse Layer 0 connections for coordination and only open a few direct links on Layer 2 for actual data flow. This keeps per-node resource usage low — low enough for a browser — and allows the network to include thousands of nodes without connection overhead becoming a bottleneck.
Putting the layers to the test
One of the most impressive aspects of Streamr’s trackerless network is how it maintains low latency even as it scales. By “low latency,” we mean the time it takes to deliver a message to all subscribers — ideally just above the raw internet transit time.
Experiments showed that with locality-based clustering enabled, the average message propagation delay stayed under ~120 ms even in a 2,000-node network. Without locality (random mesh), the delay was nearly 300 ms at just 500 nodes.
In Part 2, we’ll share the methodology and full results of these scalability tests, proving the performance and scalability of the multi-layer decentralized network.
If you have any questions about the blog, feel free to ask on the Streamr Discord.