
In late January 2020, the Streamr Network developer team met up in Helsinki for a two-day technical workshop to discuss the Network’s next steps. It was very fruitful. Half-a-dozen major development areas were discussed and debated in detail, and many new ideas were born. In this blog post, we will give some insight into these discussions, our thinking, and the approaches presented during the workshop.
For those who are already quite familiar with our Network development, feel free to skip over the ‘Background’ section, which sets out the developments to date, our overall strategy and milestones. The rest of the post is divided into the topics we discussed during the workshop.
Table of Contents
Background
As many of you are aware by now, the Streamr developer team achieved the first major Network milestone of the Streamr project, nicknamed ‘Corea’, with the release of the Network software in October 2019 in Osaka, Japan. The aim of Corea was to replace Streamr’s then-centralized cloud-based prototype with a peer-to-peer network and protocol. This goal was met, and the pub/sub system available to users today (be it indirectly via the Core webapp or directly via SDKs and APIs) is formed by nodes interconnected as a peer-to-peer network.
The work we put into Corea not only validated that pub/sub systems implemented using peer-to-peer networks can rival traditional centralized solutions (expect a whitepaper on this soon!), it also provided us with valuable insights into the technicalities surrounding peer-to-peer networking. To put it simply, Corea was all about peer-to-peer networking.
But we are not done yet. In accordance with the strategy of “moving towards decentralization in steps whilst always providing working software for our users”, Corea specifically addressed the networking subset of all problems that need to be solved for “full” decentralization to become reality. The two remaining areas that need to be solved are security and incentivisation.
The next milestone, nicknamed ‘Brubeck’, will focus on removing the security-related obstacles to decentralization. In Corea, while nodes do operate peer-to-peer, the networks themselves remain centralized because nodes need a certain level of trust between them, when run as part of the same network. Brubeck will remove this trust requirement, enabling truly public networks to emerge that are reliable, and that anyone can join in as a node without fear of eavesdropping or censorship. Encryption, as well as prevention and mitigation of network attacks, will be the focus of this milestone.
At that point we’ll be left with a final piece of the puzzle: why would anyone run a node? Incentivisation is what the last milestone, ‘Tatum’, will address. Tatum will add an incentivisation layer to the Streamr Network, leading to a data brokerage market where nodes sell their system/bandwidth capacity to data publishers and subscribers in exchange for DATA tokens. After Tatum is released, all the major elements will be in place for a reliable, fully decentralized, public, peer-to-peer network to emerge and become the real-time data backbone of the future data economy.

Clients as nodes
An overarching topic that ties into many of the later topics in this post, is the idea of turning Streamr clients into actual network nodes. We have had this idea in the back of our minds for a long time (inspired by Mustekala among other things) and we think it’s finally time to pull the trigger on this one.
Before diving into this concept, let’s first take a step back to understand the present situation. What we currently have are clients and nodes that operate as different software. We also have two separate protocols: node-to-node and client-to-node. There is a substantial conceptual and code overhead that comes into play when clients and nodes are separate entities like this. While this model isn’t necessarily bad (Ethereum uses a similar model, for example), there is a maintenance overhead to this approach. But there also seem to be many perks and elegant solutions that come into play when moving to the model where clients become nodes.
Going forward, clients will be nodes. We will be able to utilise the same networking code for both nodes and clients, thereby reducing the total amount of code and repetition of logic in the project. We will also be able to collapse the two protocols (client-to-node and node-to-node) into one. Clients will be able to participate in propagation if they so desire, which adds size and capacity to the Network as a whole. Clients (as nodes) will be connected to multiple nodes as opposed to a single one, making censorship attacks harder to carry out. Lastly, clients will communicate directly with trackers, helping us solve scalability issues, as explained in the next section.
To pull this off, we will replace our WebSocket-based node-to-node communication implementation with one based on WebRTC. WebSocket and WebRTC are useful in that they both work in the browser and in Node.js with a compatible API. But WebRTC has the added benefit of having mechanisms to work around firewalls and NATs, thereby increasing the chance of successful peer-to-peer connections being established over consumer environments such as browsers.
We have already started working on the WebRTC implementation. However, we still need to validate a couple of things: what are the performance characteristics of WebRTC, and how well does WebRTC really fare in establishing connections to peers behind NATs?
Scaling
One of the most important aspects of this project is scaling. The performance characteristics of the Streamr Network, be it latency or throughput, should not degrade as the number of nodes, streams, subscribers, and publishers in the Network increases. Obviously, if only the demand-side, i.e. streams, subscribers, or publishers, grow in numbers while nodes do not, the Network will run into issues because the supply simply isn’t there. But let’s assume for this discussion that the future incentive mechanism will ensure that the number of nodes grows proportionally to the number of streams, subscribers, and publishers.
Think about it like this: you are subscribed to a stream with a moderate amount of data, say 10 messages per second, and you observe an average latency of 100 ms. Let’s say the network is very small — five nodes. As the network grows to say 500 nodes, handling dozens of streams, and thousands of publishers and subscribers, you should still observe 10 messages per second arriving with an average latency of 100 ms (provided the network node capacity has increased proportional to the number of streams, subscribers, and publishers). In other words, your experience should be independent of all other activity and the size of the network.
We have not hit a fundamental wall with scaling. And based on our knowledge, there are no such limits. We’ve had to take a few shortcuts in our implementation though, which are not optimal from the perspective of scaling. Thankfully, all these are implementation-specific and thus easily solvable.
One of the key issues has been the way clients have worked. Specifically, they have contacted a load balancer, which has then randomly assigned them to one of the nodes. If you think about each client having a specific set of streams they are interested in (either as subscribers or publishers), following this random node assignment logic for many clients will lead to a situation where every node gets assigned to every stream. This means, in turn, that any message sent to the network gets propagated to every node, which obviously does not scale well as new nodes and clients join the network.
What we really want is interest clustering. Given the set of all streams present in the Network, a node should only be assigned to a subset of them. Looking at it from another angle: an individual stream should be assigned to N nodes, where integer N should be proportional to the message rate and amount of subscribers and/or publishers interested in that stream, i.e., demand.
To achieve this, we need to re-direct connecting clients to appropriate nodes according to known stream assignments. Luckily, as discussed above in the ‘Clients as nodes’ section, we are moving to a model where clients themselves become nodes, which nicely facilitates this need. In the future, the centralized load balancer will no longer be needed, as clients will contact trackers as nodes themselves and inform the trackers of the streams they are interested in. The trackers will then assign peers for the clients in a way that allows for efficient and scalable network formation. This means that increased demand for a stream will lead to increased capacity as intended.
Robustness and security
As mentioned above, the main goal of our next milestone, Brubeck, is to enable public networks by allowing anyone to join an existing network as a node without risking censorship or eavesdropping (and without the capability to censor or eavesdrop on others). These networks should also be reliable and be able to mitigate certain network attacks. In the January workshop, we came up with the steps that need to be implemented for this vision to come to fruition.
Firstly, the removal of the load balancer and having clients become nodes, as discussed in the previous sections, are necessary steps to realising Brubeck. Relying on a centralized load balancer for node discovery is antithetical to having a public decentralized network. What’s more, it is not a scalable solution as discussed above.
Secondly, it will be vital in the Brubeck stage that messages in the Network be signed and encrypted. Signing messages prevents the tampering of them after publishing and provides proof of origin. Encryption enables confidentiality of data, which is especially important in a public network where messages get relayed through untrusted nodes.
Finally, effort must be put into mitigating or altogether preventing network-related attacks. DDoS mitigation schemes and rate limiting policies will need to be introduced to avoid trivial takedowns of the Network. We also need guards against eclipse and Sybil attacks. Having enough nodes assigned to a stream’s topology is one approach to mitigate takeovers by making them more expensive to perform. Increasing node degree — the number of other nodes a node will connect to — also helps mitigate these types of attacks. Reputation metrics could be used too, as well as having the trackers enforce certain topological constraints on the Network. Yet another idea is to add a cost to becoming a node. This cost could be achieved with either proof-of-work or staking mechanisms.
Peer discovery
An important part of the Network is how nodes get to know about each other so they can form connections. This is often referred to as ‘peer discovery’. In a centralized system, you’ll often have a predetermined list of addresses to connect to, but in a distributed system, where nodes come and go, you need a more dynamic approach. There are two main approaches to solving this problem: trackerless and tracker-based.
In the trackerless approach, each node is responsible for keeping track of other nodes whose existence it is aware of, and regularly exchanging this information with its neighbours. This is referred to as ‘gossiping’. A result of this continuous process is that information about new nodes eventually gets disseminated throughout the network, making connections to these new nodes possible.
In the tracker-based approach, we have special peers called trackers whose job it is to facilitate the discovery of nodes. They keep track of all the nodes that they have been in contact with, and every time a node needs to join a stream’s topology, they will ask the tracker for peers to connect to.
We are still undecided on which approach is better for the Streamr Network in the long run. The tracker-based solution requires a level of trust in the trackers because they are in control of forming the connections and the topologies of the network. This control gives trackers power in the network, which they could abuse. Thankfully, there are ways to ensure that not just anyone can become a tracker in the network. For example, the owner of a stream could define a set of identities they trust to become trackers for their stream. There could also be a token-curated registry (TCR) of public trackers to serve as a default set of trackers for new streams.
It could be argued that the trackerless approach is more elegant and more decentralized than the tracker-based one. However, the problem with the trackerless approach is that it is prone to eclipse attacks. Dishonest nodes may collude and leave all honest nodes out of their gossip messages. By doing so, a sufficient number of dishonest nodes would be able to effectively censor all honest nodes from the Network. There are some ways to mitigate this problem, but there are few real-world examples of large-scale networks not vulnerable to such attacks.
Additionally, in a trackerless approach there is an incentive for nodes to behave greedily, i.e., favour connections to those nodes that are providing them with the best service (consistent low-latency messages). It is unclear whether this behaviour comes at the expense of other nodes in the network, or whether each node acting greedily actually leads to an efficient network topology for everyone.
The nice thing about the tracker-based approach is the control that the tracker has on the topology of the network. For example, a stream whose data needs to stay within a certain geographic area (say, EU), could be assigned to a specialised tracker that enforces such a constraint through GeoIP tools. Trackers also allow the topology to be optimized from a global viewpoint, ensuring each participant gets a good level of service, and one that is not at the expense of others. Controlling the topology also allows for mitigation (perhaps even prevention) of certain network attacks such as eclipse attacks. Finally, the tracker makes a nice fit for the signalling needs of the WebRTC protocol, because it can act as a STUN/TURN server.
Going forward, we will keep both approaches open. Having an increasing amount of the Streamr Network features developed will help guide us towards the better fit. In addition, we will run more experiments to understand the performance characteristics and trade-offs of each approach.

Token mechanics
Token mechanics and incentivisation are areas of focus that come up later in the Streamr milestone strategy; they are scheduled to be shipped in the Tatum milestone (following the Brubeck release). With that being said, it is imperative that we already start thinking and fleshing out the details of these topics before we even start working on implementing Tatum. These topics did spark some lively conversation and interesting concepts during our workshop.
Here are some key questions that need answers:
- How exactly should the Network reward node operators so that they behave in a way that is aligned with the interests of other parties in the Network?
- How do you determine the price discovery mechanism that results in enough of an incentive for operators to provide network capacity (by running enough nodes) whilst not becoming cost-prohibitive to the Network’s users?
- How do Network nodes prove, or how do outside parties validate, that nodes are propagating all messages in a timely manner?
- Who pays the usage fees — publishers, subscribers, or both?
- In the case of free ‘public good’ data streams, who should foot the bill?
- And how to execute all these token transfers in a tractable and efficient manner?
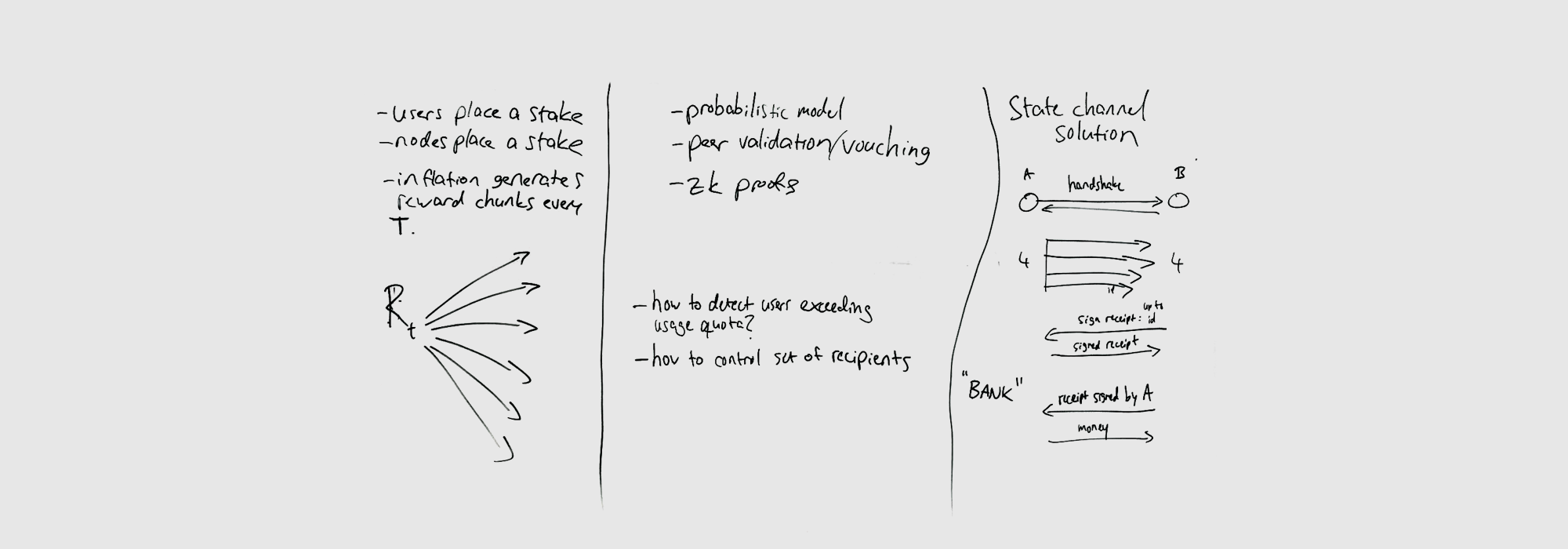
To address the question of how to validate that nodes are doing what they are supposed to, signed receipts can be generated between nodes and subscribers (or publishers). These receipts are mutual agreements between the two parties that a certain set of messages have been delivered (or published) with acceptable service thus far, and act as proof later for disputes or for collecting rewards. In the case of a dispute, both parties (node and subscriber/publisher) will need to produce a copy of their receipts to prove their side of the transaction. Or, alternatively, these receipts are presented by the node to the Network for reward collection. The amount, as well as the content, of these receipts could then determine the size of the reward.
The challenging part of the receipts is how to manage the sheer quantity of them. Doing a token transfer per receipt is not scalable. Thus alternative solutions are required.
One such solution is to use state channels. It allows for all interactions between nodes to be proven and billed accurately. Downsides include the high setup costs involved, the need to tie capital to the state channel, and high withdrawal costs in the presence of lots of interactions. To understand this state channel model better, we will need to spend some time researching Lightning Network and Raiden.
Another approach, perhaps representing the opposite end of the spectrum of solutions, is to use something we refer to as the Staking + Inflation model. In this model, users of the Network (subscribers and publishers) allocate stakes of DATA to a smart contract in exchange for access to the Network. The amount staked determines the user’s quota; the amount of Network traffic they are entitled to. Then at every time step T, we apply a small percentage-based fee to each stake and redirect the collected pot to node operators. This is the “inflation” step.
One benefit of the Staking + Inflation model is that the “inflation” step can occur infrequently, say once a day, once a week, or even just monthly. Thus we don’t have to continually be distributing tokens back and forth, but instead can do them in one go. Another positive aspect of this approach is that we can use the Monoplasma framework that Streamr originally developed for Data Unions. Here, it could be applied to distributing rewards to node operators. In this model we still need to decide on what basis to distribute the collected rewards to Network node operators in a way that reflects their individual efforts. Receipts may come in handy here when deciding the individual weights. Another challenge comes from enforcing user quotas. It is easy at a local level to see how much Network capacity a user is utilising. But doing so at a global level requires coordination between nodes and trackers. Finally, the Staking + Inflation model shares the downside of the state channel model in that capital must be allocated to use the system.
What is somewhat elegant about the Staking + Inflation model is that we can start adopting it without having to solve every related problem at once. We can start off by assigning uniform weights to node operators during payoff (every operator gets paid the same) and by settling for local or semi-global user quota limits. While this obviously wouldn’t solve all issues, allowing certain malincentives to exist in the system, it allows us to introduce token economics to the Network quite early, providing immediate utility for the DATA token on the Network layer. We can then iron out the details later on, to better align the incentive mechanism with the goals of all participants of the Network.
The above section offers just two high-level examples of potential approaches — it is in no way an exhaustive list. In the months ahead, we will spend more time thinking about the trade-offs of different models and coming up with ideas to make seemingly intractable problems into ones that can be solved, or at least partially solved, within acceptable constraints. Perhaps probabilistic approaches will help here as well. In fact it won’t be just Streamr doing this work. We’re working with token economics experts BlockScience to help bring this vital but highly specialised work to fruition.
Storage
In addition to real-time delivery to subscribers, it is often useful to ensure messages are stored. Replaying old messages, for example, could help train and test models. Additionally, having messages stored is useful in the case of temporary loss of connectivity between a subscriber and a node. When the subscriber is able to eventually reconnect, it can retrieve the messages it missed.
Storing data is useful, but it is a different challenge compared to that of delivering real-time data. Going forward, the project’s goal is to “outsource” storage by allowing anyone to run a storage node in the Streamr Network. This will, in turn, create an open, permissionless storage market within the Streamr Network.
We will create a standard interface that storage providers can implement and which Network users can utilise to store and retrieve data. Owners of streams will decide which storage providers they wish to rent storage capacity from. Storage providers will then subscribe to those streams and start persisting all incoming data. Owners of streams will most likely want to choose multiple storage providers for redundancy.
Encryption combined with storage poses some new challenges. Messages are stored in encrypted form, and subscribers need the capability to decrypt them later on. This means that decryption keys must be readily available for those that have been granted access to the historical content. Either the original publishers need to stay live in the Network to serve the keys upon request, or, we can look into techniques in cryptography to allow storage nodes to store partial keys.
Another challenge revolves around making sure that storage nodes are actually storing the data and not just claiming to do so. There may need to be mechanisms in place that require the storage nodes to occasionally prove that they are storing what they are claiming to (e.g. via rolling hashes or other proof systems). There could be validation bounties set up for this, incentivising new peer types called “validators” in the network to uphold the integrity of the storage nodes.
Going forward
We found the workshop to be very productive; it allowed us to exchange and debate ideas, as well as start aligning our vision towards a common shared approach.
The next concrete steps will be to turn Streamr clients into nodes and progress the WebRTC protocol implementation to a stage where we can study its merits and trade-offs. We will also be focusing on improving the scalability of the Network, something that is heavily linked to aforementioned steps.
Looking a little further ahead, Brubeck approaches. For that, we will start turning the ideas presented in the ‘Robustness and Security’ section into actionable tickets with the end goal being the ability to run secure and scalable public networks.
Finally, we have the topics of token mechanics and incentivisation that come into play in our final milestone, Tatum. As mentioned a lot of thinking needs to be spent on these areas even though Tatum is still further along the roadmap. We will be working closely with token economics experts to ensure that the conceptual solution we arrive at is tractable and properly incentivises and aligns all players interests, to ensure a secure and reliable Network.
If you have a question or comment relating to the Network for Eric, please add it in this Reddit thread. Eric can also be reached at eric.andrews@streamr.network.





