A fascinating blog post written last year by Golem Factory CTO Piotr Janiuk describes an imaginary application called Hyperbrick, which allows users to combine microservices into workflows. By happy coincidence, the Streamr Engine and Streamr Editor, as presented in our DATAcoin white paper draft, is remarkably close to Golem’s example of an ideal application in their ecosystem. This blog post is the direct result of having our minds blown while considering the overall implications of this space and its emerging tech.

A quick reminder:
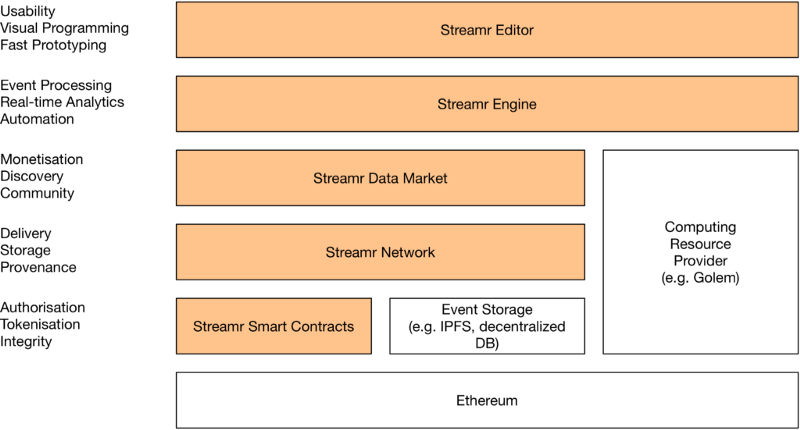
- In Streamr, “workflows” are called Canvases; they consist of modules that operate on incoming data.
- The Streamr Engine that powers it all can easily be made to run inside a Docker container, which is natively supported by Golem.
Right now, the Streamr Engine (i.e. the component which processes our data feeds) runs on more or less any computer, most often in a cloud environment. However, running in the cloud means that a centralized commercial entity like Amazon or Microsoft controls the server hardware, network, storage, and price of computation. They are also able to see who is doing what quite plainly.
In our vision, the data transport from sources to Streamr Engine nodes running on Golem would happen via the Streamr Network. This is a peer-to-peer network which ensures the data gets delivered and that it can be trusted. With Golem, the Streamr Engine, and the Streamr Network working together, computation in real-time analytics use cases could be completely decentralized, and the pricing would be determined transparently by the market. Security, privacy, and quite possibly pricing, would be vastly improved.
The current prototypes of Golem support tasks of finite computation. This works well for large, batch-oriented computation such as 3D rendering. However, for more fine-grained computation such as hosting microservices or stateful apps, support for long-running tasks/processes is required. The same goes for more obvious matters such as access to networking.
Happily, these features are indeed on the Golem roadmap. When available, these features will allow Golem to host processes such as the Streamr Engine, potentially processing hundreds of thousands of incoming requests or data points per second on a single node, and many millions on a cluster of Golem-Streamr-nodes.
As best we can tell, Streamr on Golem could bring about incredible use cases in the domains of algorithmic trading, asset tracking, anomaly detection, predictive analytics, and much more. Needless to say, we look forward to begin experimenting with Golem, and to the world of decentralized distributed compute in general. Three cheers to the #truecloud!
Questions and comments about this post and Streamr in general are appreciated! Join us on Slack, and of course feel free to follow us on Twitter as well.