The release of our new website, back in September, was a big thing for us. We built it with the intention to deliver a neatly crafted composition that feels dynamic despite not having a dedicated backend. Gathering the data from external sources quickly became a very interesting challenge.
In this article I would like to focus one such example of this — the blog section of our website — and how I managed to do some dogfooding with our Core app to create a way of keeping it up-to-date without human interaction.
So the blog section on the site previews the latest Medium blog posts and it’s driven by data delivered exclusively through Streamr. In the beginning I thought this might be best solved by creating a script that knew how to fetch blog posts from Medium and save them into a json file.
The problem with this was that someone would actually have to run the script, commit the file and push the update out. It’s far from being automatic and on top of that, every update was a separate complete redeployment. It wasn’t perfect but it worked, and more importantly it brought two new ideas into life.
First of them was a very simple proxy for Medium posts. Because it’s important for later, and because it lays down the necessary steps to get what we want quite nicely, I’ll share it here. We’re gonna refer to it later as the script.
const app = require('express')()
const x2j = require('xml2json')
const axios = require('axios')
app.get('/', (req, res) => {
axios
// (1) Let's fetch the list of recent posts.
.get('https://medium.com/feed/streamrblog')
// (2) We're gonna work with `data` portion of the response.
.then(({ data }) => data)
// (3) It's an XML. Let's convert to JSON…
.then(x2j.toJson)
// (4) …and parse to get an object.
.then(JSON.parse)
// (5) Now let's extract individual post URLs.
.then(({ rss: { channel: { item } } }) => (
item.map(({ link }) => (
link.replace(/\?.*$/, '?format=json')
))
))
// (6) And limit the list to the recent 3.
.then((data) => data.slice(0, 3))
// (7) Let's fetch individual post JSONs now.
.then((urls) => Promise.all(urls.map((url) => (
axios.get(url).then(({ data }) => data)
))))
// (8) Fetched JSONs are malformed. Let's fix them and parse on the spot.
.then((brokenJsons) => brokenJsons.map((j) => (
JSON.parse(j.replace('])}while(1);</x>', ''))
)))
// (9) Let's limit datas to their `payload` portion.
.then((posts) => posts.map(({ payload }) => payload))
// (10) And format the result! 💥
.then((posts) => (
posts.map(({
references: { User: users },
value: {
id,
creatorId,
title,
uniqueSlug,
previewContent: { subtitle: summary },
},
}) => ({
id,
title,
summary,
author: users[creatorId].name,
url: `https://medium.com/streamrblog/${uniqueSlug}`,
userImageURL: `https://cdn-images-1.medium.com/fit/c/120/120/${users[creatorId].imageId}`,
}))
))
// And render, at last.
.then(res.json.bind(res))
})
app.listen(process.env.PORT || 8001, () => {
// eslint-disable-next-line no-console
console.log("It's listening. 🎧")
})As you can see, it’s a simple expressjs app. We can have full control over it but we would have to host it ourselves and configure it so that it either follows the same-domain policy in relation to the website or make it work in a cross-domain environment with proper CORS.
The other idea was a periodically running script. It would perform an update on, let’s say, /resources/posts.json — a file that the website can reach easily.
Those two ideas aren’t bad but they have their flaws. In reality they’re certainly more complex than what I’ve managed to get across here. The amount of sysops effort necessary for making them fly is disarming. Plus, their conventional nature doesn’t exactly excite me.
It was then that the idea of using Streamr struck me. Actually, a more experienced Streamr power user and core dev, Matthew Fontana, suggested it during one of our frontend discussions. I myself have never used the Streamr stack to address a real life problem. Which is bad, because I’ve helped build it. So this was a perfect opportunity to catch up and try new things. Also, we weren’t sure it was gonna work which make it even more experimental and interesting.
Table of Contents
From a script to a running canvas
The above server is exactly what I wanted to mimic in Streamr Core. Naturally, as with any programming language you have to identify your limitations. Although Core’s Canvas building feature comes with a wide collection of modules, there are situations where your hands are (or seem) tied. Most procedures from the script can be ported to a canvas without too much hassle. Let’s leave those out and focus on the ones that aren’t obvious.
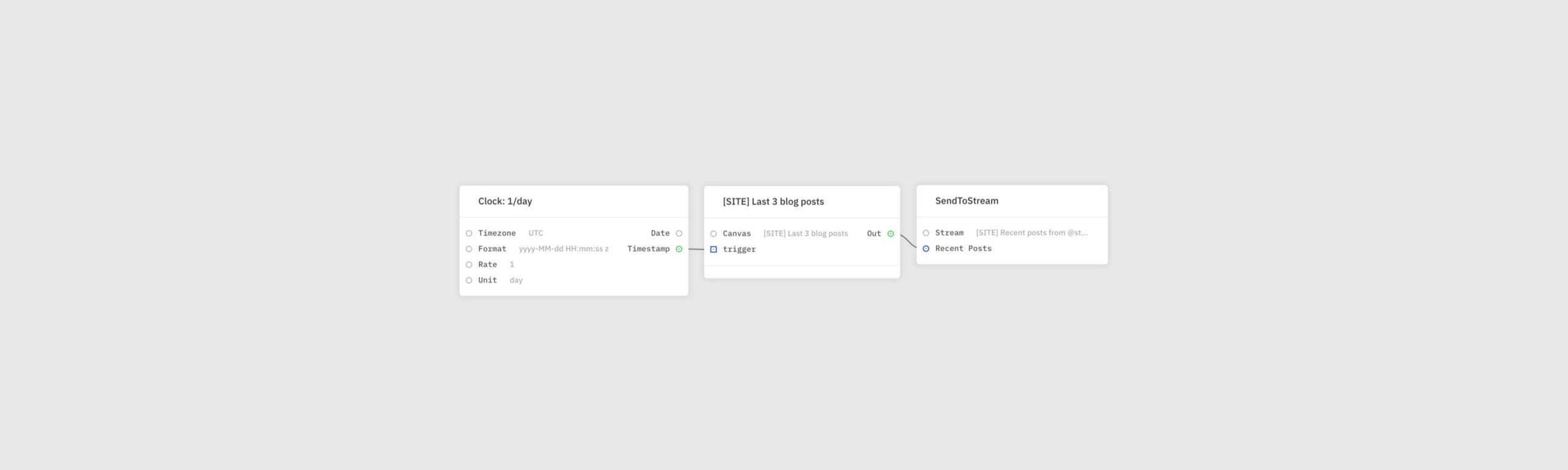
I needed to fetch blog posts directly from Medium using HTTP Request module. It accepts both JSON and plain text responses. The latter one was added to the system as a side effect of this experiment and is crucial for non-JSON responses. We’re gonna need it shortly!
There are three endpoints that we can use to fetch posts:
https://medium.com/streamrblog/latest?format=json
Very comprehensive but unfortunately, hidden behind a CAPTCHA. No BOTS allowed!https://medium.com/feed/streamrblog
Provides basic information about posts. Usable, quite inconvenient, aaand worth a shot!https://medium.com/streamrblog/<slug>?format=json
For individual posts only. <slug> is a parameter and has to be known beforehand.
The second one was the only option at that point. Since the information it gives is limited, I used it only to extract individual blog post URLs. They can be fetched later, one-by-one, using the third endpoint. A combination of the second and third endpoints gives us something very close to what would’ve been given by the first endpoint if it wasn’t blocked.
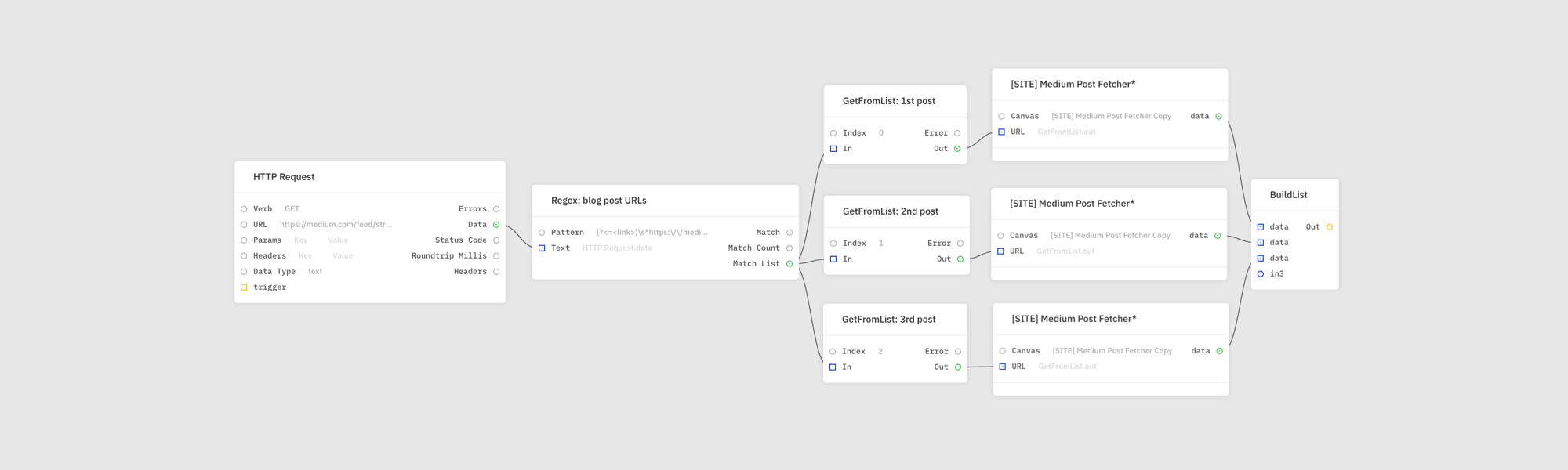
In order to extract URLs in step (5) of the script we first convert XML to JSON in step (3). I couldn’t do the same in the editor. XML parsing module doesn’t exist. Instead I decided to get creative and use Regex module and the following pattern:
(?<=<link>)\s*https:\/\/medium.com\/streamrblog\/[^<]+\s*(?=<\/link>)
Each match is a separate blog post URL. I replaced the query part in all of them with ?format=json and fetched them as plain text using HTTP Request. I didn’t tell the module to parse JSON because those returned by Medium are malformed and any unguarded parsing would fail. I addressed this issue in the script in step (8) and, luckily, I could do the same in the editor. I sanitized and parsed each response using Replace and JsonParser modules respectively.
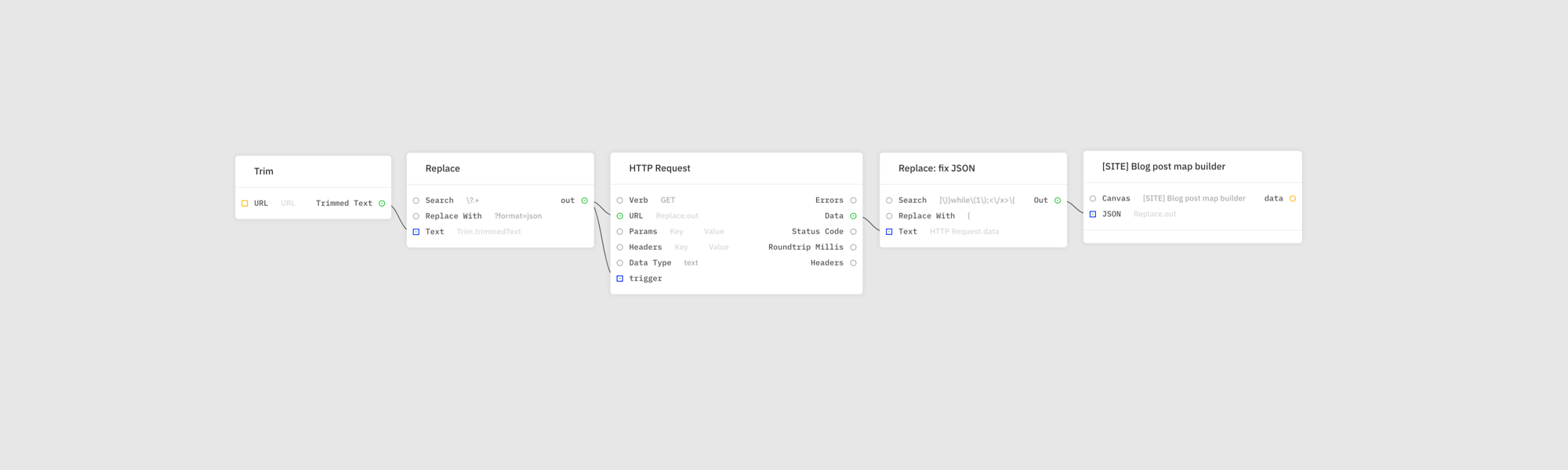
At this point I pretty much resolved all problematic parts. My canvas is near completion. Transformations in step (10) of the script could all be done with the help of modules like GetFromMap, BuildMap, Concatenate, and StringTemplate. Pretty straightforward! All that was left was to store and use the data.
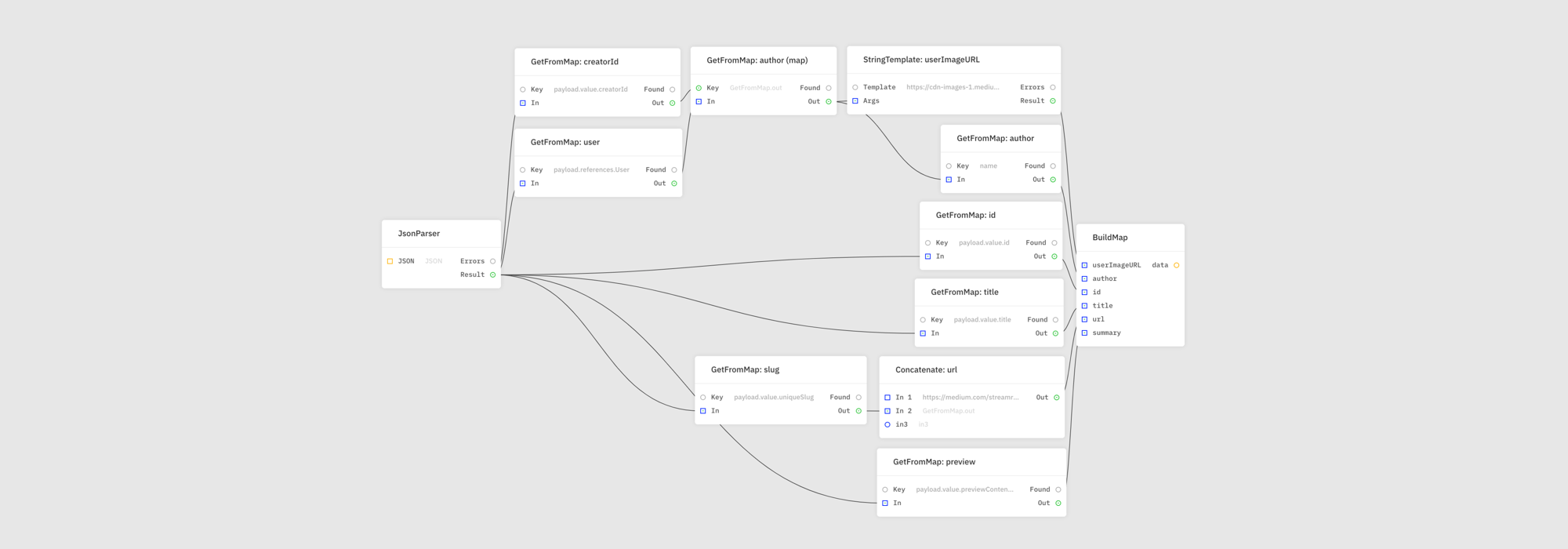
Writing to a stream
I managed to port the script to a canvas almost entirely. The last part was the storage. I used the SendToStream module to push messages to a stream. Naturally first I had to create one. I configured it so that it had a single field called recentPosts. All messages in the stream are structured like the following example:
{
recentPosts: [
{ /* First post */ },
{ /* Second post */ },
{ /* Third post */ },
],
}And posts are objects with id, title, summary, author, url, and userImageURL fields.
Reading from a stream
The most convenient way to utilise a stream in a web environment is to use streamr-client npm package. Here’s a simplified version of what has been used on the website:
import ReactDOM from "react-dom";
import React, { useEffect, useState } from "react";
import StreamrClient from "streamr-client";
const RECENT_BLOG_POSTS_STREAM_ID = "k0Tip4aVTQKHIDFD3xaJpw";
const App = () => {
const [posts, setPosts] = useState([]);
useEffect(() => {
const client = new StreamrClient({
autoConnect: true,
autoDisconnect: false
});
const sub = client.subscribe({
stream: RECENT_BLOG_POSTS_STREAM_ID,
resend_last: 1
}, ({ recentPosts }) => {
setPosts(recentPosts);
});
return () => {
client.unsubscribe(sub);
};
}, []);
return posts.length ? (
posts.map(({ id, title, summary, url }, index) => (
<div key={id}>
{!!index && <hr />}
<h3>
<a href={url} target="_blank" rel="noreferrer noopener">
{title}
</a>
</h3>
<p>{summary}</p>
</div>
))
) : (
<div>Waiting for posts…</div>
);
};
const rootElement = document.getElementById("root");
ReactDOM.render(<App />, rootElement);Conclusion
There are many solutions to my problem and I’m really glad I chose one that utilises Streamr. It allows my team to avoid spending time on maintaining another services. It’s also easy to modify, extend, or delete if we decide to. And we didn’t invest any sysops work into setting things up. A great result all round.