All decentralized networks, including blockchains and other P2P systems face the technical problem of how to gather metrics and statistics from nodes run by many different parties. Achieving this isn’t exactly trivial, and there are no established best practices.
We faced this problem ourselves while building the Streamr Network, and actually ended up using the Network itself to solve it! As collecting metrics is a common need in the cryptosphere, in this blog I will outline the problem as well as describe the practical solution we ended up with, hoping it will help other dev teams in the space.
Table of Contents
The problem with gathering metrics
Getting detailed real-time information about the state of nodes in your network is incredibly useful. It allows developers to detect and diagnose problems, and helps publicly showcase what’s going on in your network by building network explorers, status pages and the like. In typical blockchain networks, you can of course listen in on the broadcasted transactions to build block explorers and other views of the ledger itself, but getting more fine-grained and lower-level data – like CPU and memory consumption of nodes, disk and network i/o, number of peer connections and error counts etc – needs a separate solution.
One simple approach is that the dev team sets up an HTTP server with an endpoint for receiving data from nodes. The address of this endpoint is then hard-coded to the node implementation, and the nodes are programmed to regularly submit metrics to this endpoint. However, authentication can’t really be used here, because decentralized networks are open and permissionless, and you won’t know who will be running nodes in order to distribute credentials to those parties. Exposing an endpoint to which anyone can write data is a bad idea, because it’s very vulnerable to abuse, spoofing of information, and DDoS attacks.
Another approach is to have each node store metrics data locally and expose it publicly via a read-only API. Then, a separate aggregator script run by the dev team can connect to each node and query the information to get a picture of the whole network. However, this won’t really work if the nodes are behind firewalls, which is usually the case. The solution also scales badly, because in large networks with thousands of nodes, the aggregator script is easily overwhelmed trying to query the data frequently from each node.
Both the “push” and “pull” approaches outlined above can be refined and improved to mitigate their inherent shortcomings. For example, originally built for monitoring Substrate chains, Gantree first stores data locally and then uses a watchdog process to sync metrics to the cloud. To avoid the problem of a publicly writable endpoint, node operators need to sign up to the service and obtain an API key to be able to contribute metrics.
However, a fully decentralized approach is certainly possible, which decouples the data producer and data consumer, requires no explicit sign-up, and leverages a decentralized network and protocol for message transport.
Requirements
Let’s list some requirements for a more solid metrics collection architecture for decentralized networks and protocols:
- Metrics collection features shouldn’t increase the attack surface of nodes
- Metrics sharing should work across firewalls without any pre-arrangements; metrics consumers should not need to directly connect to the nodes
- The solution should scale to any number of nodes and metrics consumers
- Metrics data should be signed, validateable, and attributable to the node that produced it
- Metrics data should be equally accessible by everyone
- It should be possible to query historical metrics for different timeframes
- Contributing metrics should work out of the box without node runners having to sign up to any service.
The solution, part 1: node-specific data via node-specific streams
The solution is based on a decentralized pub/sub messaging protocol (in my example, Streamr) to fully decouple the metrics-producing nodes from the metrics consumers. Nodes make data available via topics following a standardized naming convention, and metrics consumers pick-and-mix what they need by subscribing to the topics they want. In the Streamr protocol, topics are called streams and their names follow a structure similar to URLs:
domain/path
The path part is arbitrarily chosen by the creator of the stream, while domain is a controlled namespace where streams can be created only if you own the domain. In Streamr, identities are derived from Ethereum key pairs and domain names are ENS names. If your network uses different cryptographic keys, you can still derive an Ethereum key pair from the keys in your network, or generate Ethereum keys for the purpose of metrics.
In our own metrics use case, i.e. to gather metrics from the Streamr Network itself, each node publishes metrics data to a number of predefined paths under a domain they automatically own by virtue of their Ethereum address:
<address>/streamr/node/metrics/sec
<address>/streamr/node/metrics/min
<address>/streamr/node/metrics/hour
<address>/streamr/node/metrics/day
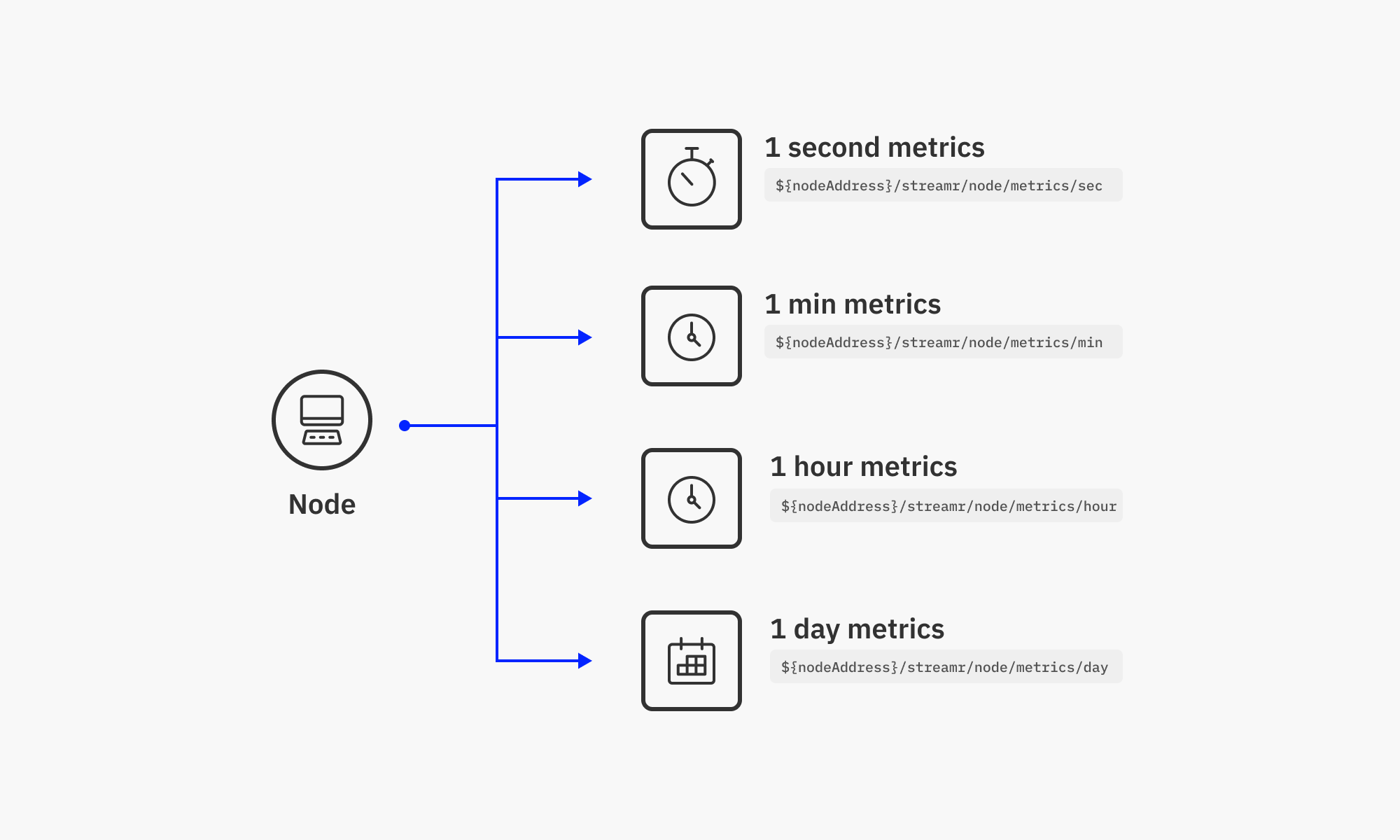
The node publishes data at different frequencies to these four streams. The sec stream contains high-frequency metrics updated every few seconds, while the day stream contains one aggregate data point per day. The different streams are there to serve different timeframes of inspection; a label showing the realtime value would subscribe to the sec stream, while a chart showing the value of a metric for one year would query historical data from the day stream. It’s important to activate storage for the streams, especially the min, hour, and day ones, to enable historical data to be retrieved.
Data points in the streams are just JSON objects, allowing for any interesting metrics to be communicated:
{ "cpu_load_pct": 0.65,"mem_usage_bytes": 175028133, "peer_connections": 39,"bandwidth_in_bytes_per_sec": 163021, "bandwidth_out_bytes_per_sec": 371251,...}Additionally, each data point is cryptographically signed, allowing any consumer to validate that the message is intact and originates from the said node. End-to-end encryption is not used here, as the metrics data is intended to be public in our use case.
The solution, part 2: computing network-level data
With the above, node-specific metrics streams can now be obtained by anyone to power node-specific views, and various aggregate results can also be computed from them. For people in the Streamr community, including those of us working on developing the protocol, aggregate data about the Streamr Network is very interesting.
To compute network-wide metrics and publish them as aggregate streams, an aggregator script is used. The script subscribes to each per-node metrics stream, which it finds and identifies by the predefined naming pattern, computes averages or sums for each metric across all nodes, and publishes the results to four streams:
streamr.eth/metrics/network/sec
streamr.eth/metrics/network/min
streamr.eth/metrics/network/hour
streamr.eth/metrics/network/day
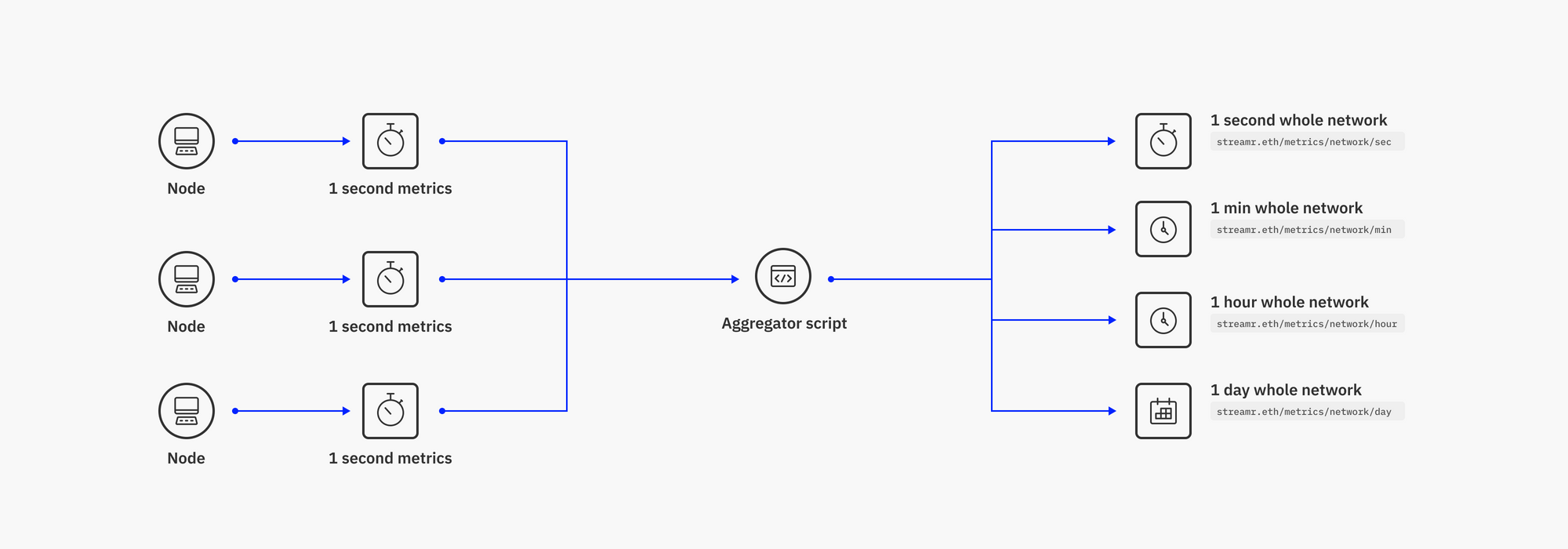
The different timeframes seen here serve a similar purpose as the timeframes seen in the per-node metrics streams. Note that these streams exist under the streamr.eth ENS name as the domain, making the names of these streams more human-readable and indicating they are created by the Streamr team.
The metrics streams might get used in many ways; a network explorer dapp could display the data to users in real-time with the help of the Streamr library for JS, or it could be connected to dashboards with the Streamr data source plugin for Grafana. Perhaps some people will even use this type of metrics data to make trading decisions regarding your network’s native token.
Conclusion
We were able to solve our own metrics collection problem using the Streamr Network and protocol, so a similar approach might come in handy for other projects too. Most of the developer tooling in the crypto space is still new and immature; many problems in decentralized devops including metrics and monitoring are missing proper solutions. I hope this post helps outline some best practices, gives an example of how to model the metrics streams, and shows how to derive network-wide aggregate metrics from the per-node streams.
Sharing metrics data in a decentralized setting is always optional, because each node is fully controlled by the person who runs it. To make decentralized metrics collection even more sophisticated, the Data Unions framework can be used to incentivise node operators to share metrics. However, that’s a topic we can explore in another blog post. Until next time!




